
Wir sind überzeugt: Software-Entwicklung hat sich seit November 2025 fundamental verändert. Was vorher als Senior-Skill galt (Architektur, Code-Review, Geschwindigkeit), bleibt wichtig. Aber das tägliche Tippen ist agentic geworden. Senior-Engineer wird neu definiert: über aktuelle Tool-Reife, nicht über Erfahrungsjahre. Und die meisten Engineering-Teams in Deutschland haben noch nicht ernsthaft angefangen.
Das hat eine Konsequenz, die kein CTO 2026 ignorieren kann: Hiring muss komplett anders passieren. Die Stellenausschreibung von gestern sortiert genau die Experten aus, die den Sprung zum Agentic Engineer schon gemacht haben. Wir sehen das in jedem zweiten Gespräch.
Dieser Artikel ist die Übersicht zum gesamten Themenblock Agentic Engineering und Hiring 2026: was sich verändert hat, warum Speed zu Judgment wandert, wie der falsche Filter aussieht, was stattdessen ins Briefing gehört, wie das Pacemaker-Modell funktioniert. Die bestehenden Vertiefungen zu Awareness, Diagnose, Sourcing und Selection sind in der Funnel-Übersicht am Ende verlinkt; das Pacemaker-Modell, Governance-Patterns und Banking folgen in den kommenden Wochen.
Karpathys Pivot: “Vibe Coding ist passé”
Der Begriff Agentic Engineering hat einen klaren Ursprung. Und einen Vorgänger, den derselbe Mann nach genau einem Jahr selbst kassiert hat. Wer das neue Vokabular der AI-Engineering-Welt 2026 verstehen will, fängt mit dieser Geschichte an.
Im Februar 2026 hat Andrej Karpathy, früher Director of AI bei Tesla und Mitgründer von OpenAI, bei Sequoias AI Ascent einen Begriff zurückgezogen, den er ein Jahr zuvor selbst geprägt hatte. “Vibe Coding”, die Praxis, einer KI ohne Code-Review zu vertrauen, sei passé. Der neue Default heiße Agentic Engineering.
Karpathys Begründung ist präzise:
“Agentic, weil du den Code in 99% der Fälle nicht mehr selbst schreibst, sondern Agenten orchestrierst. Engineering, weil dahinter Kunst, Wissenschaft und Expertise stehen.”
Der Unterschied ist nicht semantisch. Er ist operativ. Karpathy selbst hat im Dezember 2025 sein eigenes Verhältnis von 80% Coden / 20% Delegieren auf 20/80 umgedreht. Das ist der gleiche Mensch, anderer Operationsmodus.
Wie groß dieser Sprung historisch ist, formuliert Boris Cherny, Erfinder und Lead-Engineer von Claude Code bei Anthropic, in einer Renaissance-Parallele: “Vor der Druckpresse im 15. Jahrhundert konnten ungefähr 10 Prozent der europäischen Bevölkerung lesen. Die Druckpresse wurde erfunden, und über die nächsten paar hundert Jahre stieg die globale Alphabetisierung auf 70 Prozent.” Übertragen aufs Software-Coden 2026: “Software wird etwas vollständig Demokratisiertes, das jeder machen kann.” Wer 2026 noch glaubt, der Shift sei vergleichbar mit Cloud oder Mobile, denkt zu klein. Der bessere Vergleich ist die Druckpresse.
Im April 2026 ist das nochmal deutlicher geworden: Mit Claude Opus 4.7 und GPT-5.5 ist eine neue Reife-Stufe erreicht. Das ist kein gradueller Fortschritt mehr. Das ist ein anderer Reife-Level.
Wer den Begriff weiter verfolgen will, findet bei Simon Willison eine kapitelweise Pattern-Bibliothek ab Februar 2026, bei IBM eine konzeptionelle Definition, und bei Codecentric einen der wenigen deutschen Tech-Blog-Artikel zum Thema. Unsere eigene Definitions-Vertiefung mit der Drei-Stufen-Unterscheidung Vibe Coding, Agentic Coding und Agentic Engineering steht in Was ist Agentic Engineering.
Was sich seit November 2025 messbar verändert hat
Die METR-Studie ist der direkteste Vorher-Nachher-Beleg, weil sie dieselbe Methodik mit teils denselben Teilnehmern über die Zeit vergleicht:
- Anfang 2025: Erfahrene Open-Source-Entwickler (Median 10 Jahre Erfahrung) brauchten mit AI 19% länger als ohne. Konfidenzintervall +2% bis +39%. Ursache: Prompt-Overhead, Verifikationsaufwand, Kontext-Verluste bei den damaligen Tools.
- Februar 2026: Dieselben Teilnehmer arbeiten jetzt rund 18% schneller mit AI. Konfidenzintervall -38% bis +9%.
Ein Swing von 37 Prozentpunkten in 12 Monaten, bei identischer Studienmethodik. METR selbst nennt die Adoption agentischer Tools als Hauptursache. Nicht bessere Prompts. Anderer Workflow.
Noch interessanter: METR schätzt die eigenen Zahlen als Unterschätzung des realen Effekts. Der Grund: Die produktivsten AI-Nutzer steigen aus der Studie aus. 30 bis 50 Prozent der Teilnehmer reichen Tasks bewusst nicht ein, weil sie sie ohne AI nicht mehr machen wollen.
Der Stichtag: Agentic Engineering wird Enterprise tauglich
Der Reife-Sprung lässt sich auf wenige Releases zurückführen. Diese Tabelle ist der härteste Beleg, dass “Agentic Engineering” keine sprachliche Mode ist, sondern eine technologische Verschiebung mit klarem Datum.
| Datum | Release | Was sich operativ änderte |
|---|---|---|
| 24. November 2025 | Claude Opus 4.5 | Multi-Step Tool Use wurde verlässlich, der Stichtag |
| 11.–18. Dezember 2025 | GPT-5.2-Codex | Vergleichbare Reife bei OpenAI |
| 18. Dezember 2025 | Agent Skills | Wiederverwendbare Context-Packages, Team-Wissen wurde modular |
| 5. Februar 2026 | Claude Opus 4.6 | Agent Teams out-of-the-box, koordinierte Multi-Agent-Ausführung |
| 5. März 2026 | GPT-5.4 | Sprung auf OSWorld (Desktop-Automation) von 64% auf 75% |
| 17. April 2026 | Claude Opus 4.7 | SWE-bench Verified von 80,8% auf 87,6%, erstmals über die 80-Prozent-Marke |
| 22. April 2026 | GPT-5.5 | Terminal-Bench 2.0 auf 82,7% State-of-the-Art |
| 28. April 2026 | Claude Code v2.0 | Rust-Control-Plane, Operator-Workflows, Desktop-Dashboard für Enterprise |
Wer heute produktive Agentic-Engineering-Praxis vorweist, hat sie zwangsläufig zwischen November 2025 und April 2026 aufgebaut. Länger gibt es das nicht.
Greg Brockman, President von OpenAI, hat denselben Sprung aus Anbieter-Perspektive bestätigt: “Allein im Laufe des Dezembers sind wir bei diesen agentic Coding-Tools von 20 Prozent geschriebenem Code auf 80 Prozent gesprungen. Das heißt, sie gehen von Nebenschauplatz zu der zentralen Sache, die du den Tag über tust.” Ein Faktor 4 in einem Monat. Das ist die Reife-Beschleunigung, die hinter den Release-Daten in der Tabelle steht.
Wer wissen will, wie das in der Spitze aussieht: Cherny hat bei Sequoias AI Ascent 2026 berichtet, dass er an einem Tag 150 Pull Requests gemerged hat. Sein Setup: 5 bis 10 parallele Sessions, mehrere hundert Agents gleichzeitig, dazu Dutzende cron-getriggerte Loops, die nachts laufen. Agents, die CI-Health überwachen, PRs auto-rebasen, Twitter-Feedback clustern. “Loops sind die Zukunft”, sagt Cherny. Genau diesen Praxis-Sprung hat Anthropic intern zwischen Oktober und November 2025 erlebt, fast deckungsgleich mit dem METR-Befund.
Cherny formuliert es noch schärfer: “Für mich ist Coden gelöst.” Mit dem Zusatz: “Für mich. Nicht überall: Es gibt große komplizierte Codebases, seltsame Sprachen, die das Modell noch nicht beherrscht.” Dieser ehrliche Disclaimer ist genauso wichtig wie die Behauptung. Was bei Anthropic in einer 100% TypeScript/React-Codebase funktioniert, ist nicht die Realität jeder DAX-Bank. Aber es ist die Reife-Spitze, die zeigt, was möglich ist.
Anthropic als Praxis-Beweis: 74 Releases in 52 Tagen
Wenn jemand Zweifel hat, ob das Enterprise-tauglich ist, hilft ein Blick auf Anthropic selbst. Zwischen dem 1. Februar und dem 24. März 2026 hat Anthropic 74 Produkt-Releases ausgeliefert, über alle Produktlinien hinweg.
Das sind 1,4 Releases pro Tag. Parallel.
Die Liste der Release-Highlights würde bei den meisten Enterprise-Software-Firmen mehrere Quartale füllen: Claude Opus 4.6, Sonnet 4.6 mit 1M-Token-Context-Window, Memory für alle Nutzer kostenlos, Excel- und PowerPoint-Integration, Code Review, Code Security, Computer Use, Voice Mode, Channels für Telegram und Discord.
Der entscheidende Punkt für jeden CTO:
Anthropic baut Claude Code mit Claude Code. Etwa 80% der technischen Mitarbeiter nutzen es täglich. 90% des Codes in Claude Code ist von Claude Code selbst geschrieben.
Ein Team, das so abliefert, ist nicht größer. Es ist anders gehebelt: Senior-Leute. Scharfes Urteilsvermögen. Hoher AI-Tool-Einsatz. Keine Mittelschicht, die das Tempo bremst.
Was das in Deutschland heißt
In Deutschland sind im Mai 2026 rund 149.000 IT-Stellen unbesetzt, 12.000 mehr als ein Jahr zuvor. 70% der Unternehmen melden Mangel an IT-Fachkräften (Bitkom Studienbericht 2026).
Gleichzeitig setzen erst 21% der Großunternehmen mit 250+ Mitarbeitern KI aktiv gegen den Fachkräftemangel ein (Bitkom Pressemitteilung Februar 2026). Bei Mittelständlern mit 50–249 Beschäftigten sind es 12%, bei kleineren 7%. Bei Kleinst-Unternehmen unter 10 Mitarbeitern: 2%.
42% der Unternehmen erwarten, dass durch KI neue Berufsbilder in der IT entstehen. Aber zwischen “erwarten” und “haben jemanden eingestellt, der so arbeitet” liegt eine große Diskrepanz, um die es in diesem Artikel geht.
Speed ist commodity geworden. Judgment ist der neue Engpass.
Solange “Code schreiben“ knapp und teuer war, war Geschwindigkeit der Hebel. Schnell tippen, schnell Code reviewen, schnell debuggen. Wer schnell war, war wertvoll.
Was passiert, wenn Output billig wird? Der Engpass wandert weiter. Zur Entscheidung, was überhaupt gebaut werden soll. Zur Frage, was “gut” in einem konkreten Geschäftskontext heißt. Zur Fähigkeit, einen “fast richtigen” Vorschlag von einem brauchbaren zu unterscheiden.
Sequoia hat diese Verschiebung im April 2026 in einem Essay präzise formuliert. Julien Bek, Investor bei Sequoia Capital mit Fokus auf AI-Infrastruktur, unterscheidet Intelligence (Regeln anwenden, Specs in Code übersetzen, testen, debuggen) von Judgment (welches Feature wann, welche Architekturschuld eingehen, wann shippen). AI hat die Intelligence-Schwelle überschritten. Judgment bleibt menschlich.
Konkret:
Jede AI-Verbesserung macht das Werkzeug günstiger und macht Judgment wertvoller.
Karpathy hat im April 2026 die Spreizung präzisiert: “Früher hat man vom 10x-Engineer gesprochen. Ich glaube, das verstärkt sich jetzt deutlich. 10x ist nicht der Speedup, den du bekommst. Wer wirklich gut darin ist, kommt deutlich höher als 10x.” Im Klartext: Der gute Senior, der agentic arbeitet, ist extrem gehebelt. Der schwache Senior mit denselben Tools kann sogar langsamer werden, weil er Output produziert, den niemand reviewen kann. Talent-Density im agentic-Engineering-Bereich ist 2026 nicht ein gradueller Hebel. Sie ist exponentiell.
Brockman hat das Anfang Mai 2026 noch konkreter formuliert. Sein Punkt: Wenn das Tun günstig wird, wandert die Knappheit zur menschlichen Aufmerksamkeit. “Das Machen von Dingen ist jetzt einfach. Die Frage ‘Ist das gut? Ist das, was ich wollte? Passt das zu meinen Werten?’ wird zum wichtigsten Engpass überhaupt.” Er illustriert es mit einer Anekdote: Sein Codex-Agent hat einen Slack-Kollegen für eine Frage gepingt, zwei Minuten später dessen Manager. “Das dauert zu lange, ich habe eskaliert.” Technisch korrekt, sozial daneben. Genau in dieser Lücke entscheidet sich, ob ein Engineering-Team agentic produktiv ist oder agentic chaotisch.
Wenn ein schwacher Operator mit AI in einer Stunde 500 Zeilen plausibel aussehenden, aber unbrauchbaren Code produziert: Was kostet das ein Team? Nicht die Stunde. Die Tage, in denen ein Senior das aufräumt. Die Wochen, in denen ein architektonischer Patzer durch die Codebase wandert.
AI macht schlechtes Hiring teurer, nicht günstiger. Das ist das eigentliche Argument von 2026.
Die Marktdaten bestätigen das
77% der Business-Leader sagen 2026, dass AI ihren Bedarf an spezialisiertem, fraktionalem Talent erhöht, nicht senkt. Gartner berichtet im selben Jahr, dass das Headcount-Wachstum in Engineering-Organisationen von 6% auf 2% gesunken ist, während Tech-Budgets im zweistelligen Bereich wachsen. Das Geld fließt von People zu Compute.
Tomasz Tunguz, General Partner beim VC-Fonds Theory Ventures, hat Anfang 2026 vorgeschlagen, dass Tokens jetzt die vierte Komponente von Engineering-Compensation sind: Salary, Bonus, Equity, Inference Compute. Bei Senior-Engineers liegen die Token-Kosten bereits bei über 20% der Fully-Loaded-Cost.
Der Engineering-Lead von OpenAI Codex hat berichtet, dass Kandidaten in Bewerbungsgesprächen mittlerweile fragen, wie viel dedizierte Inference-Compute sie bekommen. Nicht das Gehalt. Nicht das Equity-Paket. Compute.
Aber Compute ohne Judgment ist nur eine größere Rechnung. Tokens bezahlen Ausführung. Jemand muss entscheiden, was gebaut werden soll, wann geshippt wird, welche Tradeoffs akzeptabel sind. Das braucht Erfahrung. Senior-Leute, die solche Entscheidungen schon getroffen haben.
Wer mehr zu dieser Verschiebung lesen will: die wirtschaftliche Konsequenz für Engineering-Org-Design haben wir in unserer Token-KPI-Vertiefung ausgearbeitet.
Hiring: der falsche Filter
Was passiert, wenn ein CTO im Mai 2026 anfängt zu suchen?
Die häufigste Stellenausschreibung lautet sinngemäß: “Wir suchen einen Senior-Engineer mit jahrelanger Erfahrung in Enterprise-AI-Implementation, etablierter Agent-Toolchain und Track-Record in regulierten Umgebungen.”
Klingt vernünftig. Ist es nicht.
“Enterprise-Agentic-Erfahrung” als Hiring-Kriterium funktioniert 2026 logisch nicht. Die Methodik ist seit November 2025 produktiv reif. Das sind sechs Monate. In diesen sechs Monaten hat kein regulierter Konzern in Deutschland einen ernsthaften Agentic-Engineering-Rollout durchgezogen, weil Procurement, Legal, Datenschutz und Architektur in Quartalen denken, nicht in Wochen.
Wer Jahre verlangt, sucht eine Person, die nicht existieren kann. Die Bewerber, die sich als “Enterprise-Agentic-Veteranen” präsentieren, haben fast immer eine Lücke zwischen Anspruch und tatsächlichem Tool-Setup. Wir prüfen das in jedem Discovery-Call und finden das immer wieder.
Was den richtigen Kandidaten dabei systematisch aussortiert: Genau die Senior-Praktiker, die zwischen November 2025 und April 2026 an aktuellen Tools gearbeitet haben (nicht in zwei Jahre alten Legacy-Stacks), werden durch “Enterprise-Erfahrung” aus dem Funnel gefiltert.
Wo du die richtigen Senior-Profile stattdessen findest und welche vier Verhaltens-Anker ins Briefing gehören, steht in Senior Agentic Engineer finden 2026.
Was stattdessen ins Briefing gehört
Vier Verhaltens-Anker, die 2026 mehr aussagen als Erfahrungsjahre:
1. Aktueller Workflow statt Erfahrungsjahre. Hat der Kandidat zwischen November 2025 und heute mit drei bis fünf parallelen Agents in Worktrees gearbeitet? Schreibt er Specs vor dem Code? Nutzt er Plan-Mode? Lässt er Review-Agents über die Implementierung laufen?
2. Eigene Skills im Repo. Modulare, wiederverwendbare Context-Packages, die der Kandidat selbst geschrieben hat. Nicht heruntergeladen. Nicht aus einem Tutorial kopiert.
3. Subscription-Tier. “Welches Tier fährst du auf Claude Code?” ist 2026 eine Diagnose-Frage. Wer auf Pro für $20 pro Monat sitzt, nutzt die Tools nicht ernsthaft. Senior-Praktiker fahren Max 5x oder Max 20x, oder direkt API. Weniger ist Hobbyist-Niveau.
4. Ehrliches Fehler-Handling. “Erzähl mir einen Moment, wo der Agent kompletten Unsinn gebaut hat.” Wer nur Erfolgsgeschichten hat, hat entweder wenig echte Praxis oder keine Selbstreflexion. Beides ist disqualifizierend.
Karpathy hat im April 2026 gesagt, was dieser Artikel als Kernargument macht: “Die meisten Leute haben ihren Hiring-Prozess noch nicht für agentic-Engineering-Fähigkeit umgebaut. Wenn du Knobelaufgaben verteilst, bist du noch im alten Paradigma.” Genau das ist die Lücke, die wir mit unserem 45-Minuten-Interview-Format adressieren. Karpathy beschreibt sie, wir liefern den operativen Schritt zur Lösung.
Wie diese vier Anker in einem 45-Minuten-Interview konkret geprüft werden, haben wir als eigenes Format mit 21 konkreten Fragen ausgearbeitet: sequenziell aufgebaut, mit Green-Flag- und Red-Flag-Bewertungen pro Frage und einer Build-und-Break-Take-Home-Variante. Vertiefung im Interview-Leitfaden.
Senior-Freelancer mit Domain plus Track-Record
Domain-Tiefe ist 2026 nicht mehr Differenzierung. Sie ist Eintrittskarte.
Mit Domain meinen wir konkrete Stack- und Branchen-Tiefe: der Senior, der seit zehn Jahren Java-Spring-Boot-Backends in der Versicherungs-IT baut. Der iOS-Veteran, der weiß, wie SwiftUI in einer Codebase mit Objective-C-Altlast wirklich läuft. Die Full-Stack-Engineerin mit React- und Node-Erfahrung in High-Traffic-E-Commerce. Der Next.js- und TypeScript-Praktiker, der SSR-Caching auf Vercel und Cloudflare so lange debuggt hat, bis es saß. Das ist Domain.
Der echte USP eines Senior-Freelancers heißt Domain plus belegbarer Agentic-Engineering-Track-Record: aktuelles Tool-Setup, eigene Skills, parallele Agents, Spec-Driven-Workflow, Token-Bewusstsein. Gepaart mit der Stack-Tiefe oben entsteht daraus die Magic, die ein klassischer Senior allein nicht hinbringt. Wer das mitbringt, kann ein Engineering-Team in Wochen anders operieren lassen.
Was diese Senior-Profile von klassischen Beratern unterscheidet: Sie liefern wie jeder andere Engineer. Aber im Tempo und mit den Workflows, die das Team erst noch aufbaut. Das Team kalibriert sich am sichtbaren Beispiel.
Eine Marktbeobachtung dazu: 61% der Freelancer nutzen GenAI aktiv in ihren Workflows, bei Festangestellten sind es 40% (DemandSage 2026). Externe haben strukturellen Druck, am aktuellen Stand zu bleiben. Der nächste Auftraggeber fragt, was sie können. Festangestellte können in einem Stack einfrieren, der vor zwei Jahren entstand.
Das Pacemaker-Modell
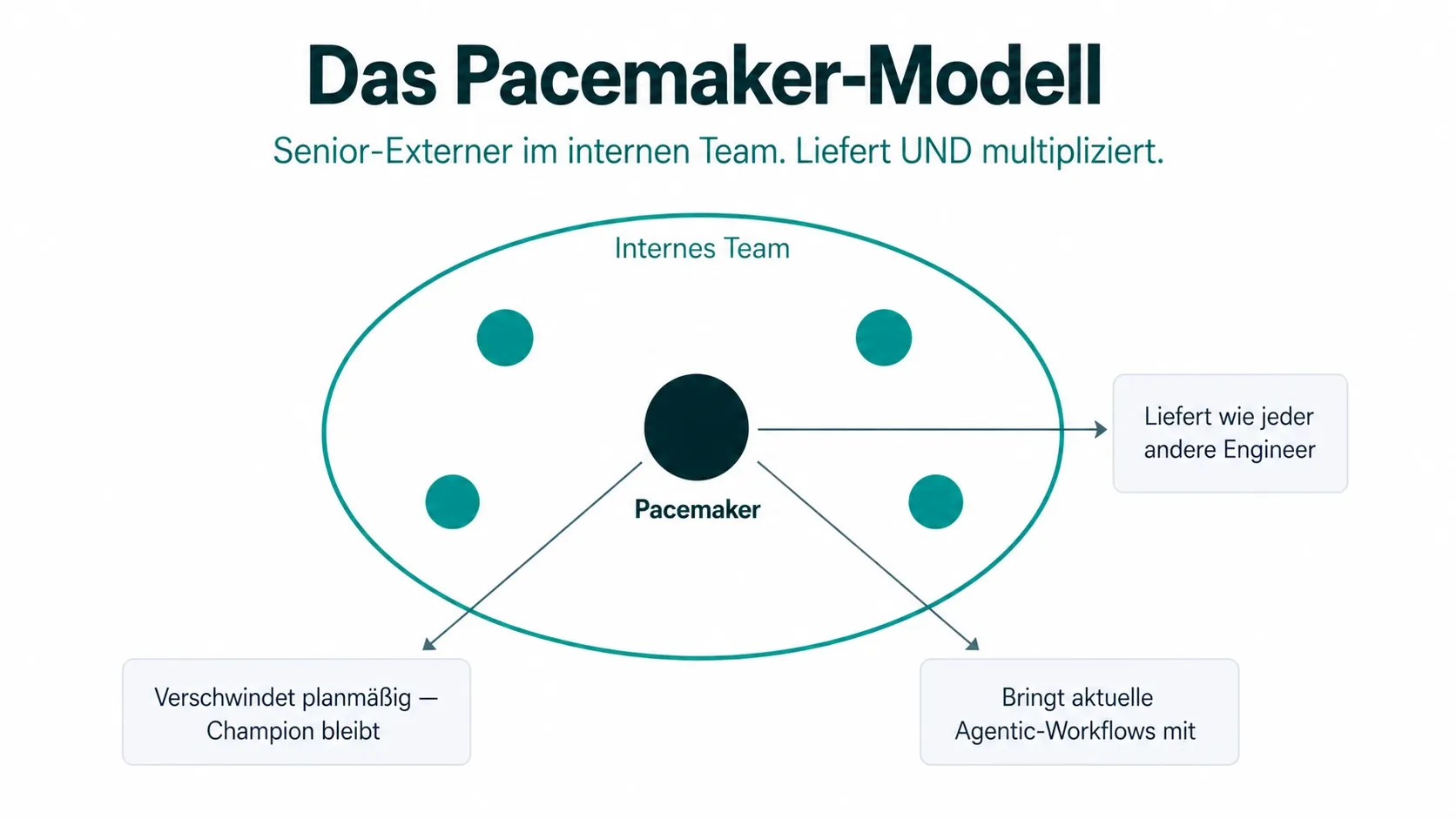
Engineering-Teams in Enterprise-Umgebungen können per Definition selten mit den aktuellen Tools arbeiten. Procurement, Legal und Security-Freigaben dauern Quartale, nicht Wochen. Was fehlt, ist die Gegenbewegung von außen. Jemand, der die nächste Stufe schon kennt und an dem sich das Team neu kalibrieren kann.
Die Lösung liegt im gemeinsamen Verständnis der Seniors, was Architektur und Best Practices angeht, gepaart mit aktuellen agentic-Workflows, die so angepasst werden, dass sie für Unternehmens-Compliance und Business praktikabel bleiben. Dafür muss aber jemand im Raum sein, der weiß, was am Zahn der Zeit ist.
Das ElevateX Pacemaker-Modell: Ein erfahrener externer Senior-Engineer mit aktueller Agentic-Engineering-Reife sitzt als reguläres Team-Mitglied mittendrin und gibt von dort den Rhythmus vor, in dem agentic gearbeitet wird.
Ein Pacemaker erhöht nicht das Tempo um des Tempos willen. Er stellt den Rhythmus her, in dem das Team agentic arbeiten kann. Geschwindigkeit ist die Folge, nicht das Ziel.
Drei Mechaniken unterscheiden das Modell von klassischer Beratung oder klassischer Interim-Verstärkung:
- Liefert UND multipliziert. Der Pacemaker ist nicht nebenher Coach. Er ist primär Engineer mit Liefer-Verpflichtung. Wissensübertragung passiert im Arbeitsalltag, nicht in Workshops.
- Sitzt mittendrin, nicht außen. Reguläres Team-Mitglied, regulärer Standup, regulärer PR-Review. Keine separate Reporting-Linie. Keine Beraterrolle.
- Verschwindet planmäßig. Wenn der Pacemaker geht, bleibt der interne AI-Champion: die Person im Team, die respektiert ist und die Workflows weiterträgt.
Das Modell ist keine Erfindung. Interim-Management arbeitet seit 30 Jahren mit derselben Mechanik. Was 2026 anders ist: Das Wissensgefälle liegt nicht zwischen Junior und Senior, sondern zwischen “vor dem agentic Sprung” und “nach dem agentic Sprung”. Der Externe bringt das Tool-Setup, die Praktiken, die Workflows. Die gibt es nirgendwo zu kaufen außer im Tun.
Vertiefung folgt in Kürze: Das Pacemaker-Modell für Engineering-Teams.
Boris Cherny hat aus seiner eigenen Anthropic-Realität beschrieben, wohin die Reise geht: “Jeder im Claude-Code-Team coded. Unser Engineering-Manager, unser Product Manager, unsere Designer, unser Data Scientist, unser Finance-Mensch, unsere User Researcher, jede einzelne Person im Team schreibt Code.” Wenn jeder coded, bricht die klassische Engineering-Org-Struktur auf. Was bleibt, sind Senior-Generalisten, die Engineering, Produkt und Domain in einer Person verbinden. Und genau die werden 2026 zu Engpass-Hires.
Wo die Grenzen liegen
Der gleiche Markt, der die METR-Daten produziert, produziert auch Befunde, die zur Vorsicht mahnen. Drei davon gehören in jedes ehrliche Hiring-Briefing 2026.
PR-Größe und Bug-Count steigen ohne Prozessanpassung. Der Faros-AI-Paradox-Report (10.000 Entwickler, 1.255 Teams, Juni 2025) zeigt: AI-Nutzer schreiben mehr Code und parallelisieren mehr. Aber PR-Größe steigt um bis zu 150%, Bugcount um 9%, DORA-Metriken bleiben flach. Der Engpass verschiebt sich vom Coden zum Review.
AI-Code altert schneller. GitClear hat 2025 eine 41% höhere Churn-Rate für AI-generierten Code dokumentiert. Erfahrene Entwickler produzieren mit AI rund 10% mehr dauerhaften Code. Der reale Gewinn ist deutlich kleiner als der gefühlte.
Security ist kein Selbstläufer. BaxBench (ETH Zürich / UC Berkeley, 2026): 62% der AI-generierten Backend-Lösungen sind fehlerhaft oder enthalten Security-Vulnerabilities. Selbst das beste Modell produzierte nur 56% sichere und korrekte Lösungen ohne spezifisches Security-Prompting.
“Savings” sind nicht automatisch real. Bain & Company hat im September 2025 die Real-World-Savings durch AI-Coding-Tools in einer Enterprise-Umfrage als “unremarkable” beschrieben.
Das ist die andere Seite der METR-Story. Die Produktivitäts-Gains sind real, bei klarem Scope, angepassten Prozessen und erfahrenen Nutzern. Ohne Prozessanpassung verpuffen sie in Review-Bottlenecks.
Genau deshalb braucht es Senior-Engineering-Erfahrung im Team, die diese Workflows beherrscht. Die fünf Workflow-Patterns aus regulierter Praxis vertiefen wir in Kürze in einem eigenen Artikel (Governance entsteht im Workflow); die Banking-Übertragung folgt separat als Agentic Engineering im Banking 2026.
Übersicht der Vertiefungen
Wer sich fragt, an welcher Stelle des eigenen Hiring-Prozesses er gerade steht, findet hier sechs Stufen mit den jeweils passenden Vertiefungen:
| Stufe | Frage | Vertiefung |
|---|---|---|
| 1. Awareness | Was ist Agentic Engineering eigentlich? | Was ist Agentic Engineering |
| 2. Diagnose | Wo steht unser Team, und was geben wir an Tokens aus? | Token-Spend als Engineering-KPI |
| 3. Sourcing | Wen suchen wir wirklich, und wo finden wir die? | Senior Agentic Engineer finden 2026 |
| 4. Selection | Wie prüfen wir Agentic-Reife konkret? | 45-Minuten-Format mit 21 Fragen |
| 5. Integration | Wie ziehen wir Wirkung daraus? | Pacemaker-Modell · Governance-Patterns (in Kürze) |
| 6. Scaling | Wie geht das in regulierten Branchen? | Agentic Engineering im Banking (in Kürze) |
Fazit: Warum jetzt
Bitkom hat die Lücke beschrieben: 149.000 unbesetzte IT-Stellen in Deutschland im Mai 2026. 70% der Unternehmen melden Mangel. Aber nur ein Fünftel der Großunternehmen setzt KI aktiv dagegen ein.
Gleichzeitig hat sich die Reife-Schwelle im April 2026 nochmal verschoben. Die Tools sind da. Die Methodik ist reif. Was fehlt, sind die Menschen, die wissen, wie man damit Wert produziert.
Die Lücke schließt sich nicht durch mehr Hiring. Sie schließt sich durch anderes Hiring. Senior-Engineering-Kapazität, die agentic operiert, ersetzt nicht ein, zwei, drei klassische Engineers. Sie verändert, was im selben Team möglich wird.
Wer im Mai 2026 noch “Enterprise-Agentic-Erfahrung mit fünf Jahren Track-Record” sucht, wartet auf eine Person, die es nicht gibt. Wer stattdessen einen Senior mit aktueller Tool-Reife ins Team holt (nicht als Berater, sondern als Engineer, der mittendrin liefert), verändert das Tempo des ganzen Teams in Wochen, nicht Quartalen.
Howie Liu, Gründer von Airtable, hat es im Hyperagent-Talk Anfang Mai 2026 mit einer Analogie verdichtet, die für Hiring-Entscheidungen zentral ist: “Stell dir Albert Einstein vor — generell hochintelligent. Aber er weiß nichts über Real Estate. Gibst du ihm das richtige Briefing — eine Playbook, ein Manual — geht er hin und löst es.” Übertragen aufs Hiring 2026 heißt das: Die Modelle sind Einstein. Was knapp ist, sind Senior-Engineers, die die Modelle mit dem richtigen Kontext füttern können. Domain-Wissen plus aktuelle Tool-Reife sind die Hebel, nicht jahrelange Erfahrung mit Tools, die es vor sechs Monaten nicht gab.
Das ist das Pacemaker-Modell. Und das ist die Hiring-Frage, die 2026 wirklich zählt.
Wenn ihr in einer ähnlichen Phase seid
Ich antworte persönlich. Schreibt mir kurz auf LinkedIn, wo ihr gerade steht: was eure Engineering-Reife ist, wo der akute Bedarf liegt, was bisher geschiefert hat. Kein Pitch, keine Form. Eine ehrliche Einschätzung, ob und wie wir helfen können.
Oder: Stellt eine konkrete Anfrage an unser Team, wir melden uns innerhalb von 48 Stunden mit einem ersten Vorschlag.
![Agentic Engineering Hiring-Interview 2026 [+21 Fragen-PDF]](/_astro/agentic-engineering-interview-featured-de.BlvVAp5j_Z9ib7o.webp)




